Por que los competidores ponen sus tiendas una al lado de la otra? - Un enfoque de Aprendizaje por Refuerzo Profundo
Alguna vez te has preguntado por que las tiendas fisicas competidoras se ubican cerca unas de otras como un cluster? Ya que vivimos en el mundo de AnyLogic, usaremos simulaciones e inteligencia artificial para analizar este misterio, pero esta pregunta es un problema clasico de Teoria de Juegos, asi que comencemos discutiendo esto desde una perspectiva de teoria de juegos que nos dara los fundamentos teoricos para desarrollar un modelo de simulacion.
Perspectiva de Teoria de Juegos
Imaginemos dos competidores que pronto abriran una nueva tienda en una comunidad en la que los clientes estan uniformemente distribuidos en terminos de ubicacion e interes por el producto vendido. Si las tiendas cooperan entre si, pueden ubicarse en posiciones que minimizan la distancia promedio recorrida por un cliente, mientras que al mismo tiempo comparten el 50% de la demanda. Este escenario colaborativo es una solucion socialmente optima y todos estarian contentos con ella.
Pero despues de darse la mano y elegir la ubicacion de sus respectivas tiendas, cada uno individualmente puede decidir cooperar o traicionar. Esto puede representarse con una tabla que muestra las recompensas de cada dueno de tienda basandose en la decision que ambos toman, junto con la recompensa para los clientes.

Si ambos cooperan, cada uno obtiene el 50% de los clientes, y los clientes obtienen la recompensa maxima.
Si solo uno de ellos traiciona, moviendose al centro de la ciudad, obtiene el 60% de los clientes y algunos clientes tienen que viajar mas, reduciendo la recompensa del cliente a 80.
Si ambos se traicionan mutuamente moviendose al centro de la ciudad, aun obtienen el 50% de los clientes pero la recompensa social esta en su punto mas bajo ya que las personas que viven en los bordes de la ciudad ahora tienen que viajar mas.
Si un dueno de tienda piensa en su propio beneficio, se presenta la siguiente mentalidad estrategica.
-
Si la otra tienda coopera, la recompensa maxima se obtendra traicionando.
-
Si la otra tienda traiciona, la recompensa maxima se obtendra traicionando.
Desde esta perspectiva, siempre es una mejor estrategia traicionar, siempre y cuando al dueno de la tienda no le importe la felicidad social. Ambos traicionandose mutuamente es el Equilibrio de Nash del sistema.
Esto es por supuesto una version simplificada del mundo ya que no considera el hecho de que podrian perder clientes por estar demasiado lejos, y tampoco consideramos la psicologia de la mente humana en estos escenarios.
Modelo de Simulacion
Ok, ahora que cubrimos el contexto, intentemos encontrar una forma de hacer que esto suceda en una configuracion de simulacion usando AnyLogic. Para hacer eso, necesitamos un negocio que sea capaz de tomar decisiones basandose en sus propios intereses egoistas; pero esto no es tan simple de conceptualizar si hay varias tiendas en una gran ciudad con muchos clientes. Entonces, para evitar meternos en el problema de hacer un algoritmo nosotros mismos, podemos usar aprendizaje por refuerzo (RL) con una recompensa igual al numero de ventas realizadas. Esta recompensa creara negocios egoistas que no se preocupan por la optimizacion social, sino solo por su propio beneficio financiero, lo cual esta bien porque asi es como se comportaron los duenos de tiendas en el ejemplo de teoria de juegos.
La ciudad se simplifica a ser un area rectangular con negocios y casas colocados aleatoriamente en algun lugar de esa area. Cada casa tiene un numero aleatorio de clientes dentro. Cuando un cliente necesita un producto (lo cual se decide por una tasa simple de 1 cada unidad de tiempo arbitraria), se movera al negocio mas cercano y siempre regresara a casa con el producto en sus manos.
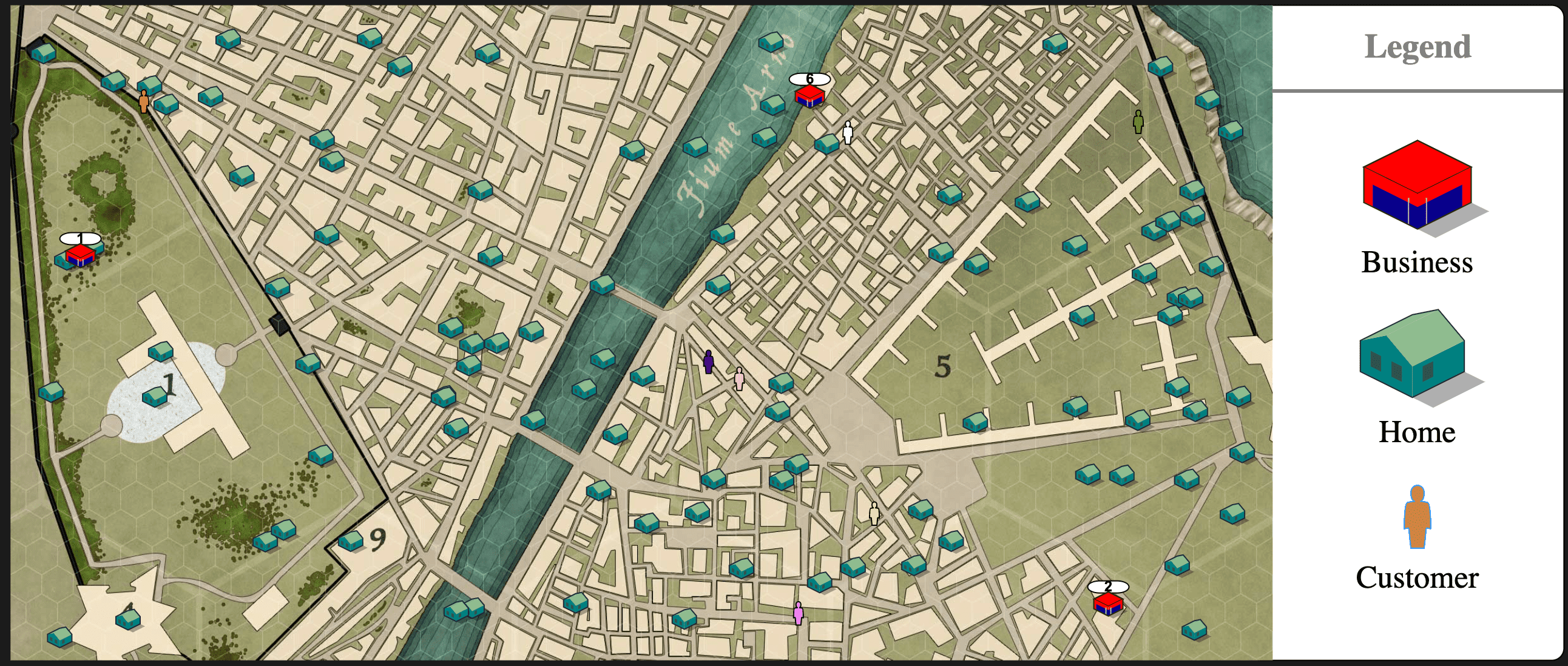
Entonces, con el modelo general creado, ahora necesitamos hacerlo listo para RL, y si estas familiarizado con RL, sabes que necesitamos crear un espacio observado, un espacio de acciones y una recompensa. Veamos cada uno de ellos por separado.
Observaciones
En todas las siguientes observaciones, tienes una variable llamada performingAgent, que es equivalente al id del agente que toma las decisiones. Esto es importante ya que solo 1 agente estara tomando decisiones durante el entrenamiento mientras que los demas permanecen en lugares fijos (explicare esto mas adelante).
Entonces, estas son las observaciones:
- La posicion de todas las casas en la ciudad con una coordenada normalizada que va de 0 a 1

- El numero normalizado de personas en cada casa. 0 si solo hay 1 persona, y 1 si hay

- Las coordenadas normalizadas de los otros negocios.

- Las coordenadas normalizadas del negocio que esta realizando una accion.

Recompensa
Se obtiene una recompensa de 1 cada vez que se realiza una venta.
Accion
Se definen nueve acciones: cuatro de ellas estan relacionadas con movimientos paralelos a los ejes x e y, cuatro de ellas con movimientos en diagonal y la ultima accion es no moverse en absoluto. La distancia movida por el agente despues de cada accion es fija y elegida arbitrariamente.
Entrenamiento usando Pathmind
Al momento de escribir este articulo, Pathmind no tiene una funcion que permita entrenamientos independientes para multiples agentes que compiten entre si con diferentes e independientes sistemas de recompensa, asi que lo que necesitamos hacer, como se explico previamente, es entrenar un negocio individual mientras mantenemos a los demas en una posicion fija (o moviendose aleatoriamente). Y si queremos usar una configuracion de competencia con n competidores, necesitamos entrenar el modelo, con una configuracion inicial que define que negocio va a tomar las decisiones. Hacemos esto con una variable aleatoria de la siguiente manera (representando el parametro performingAgent del que hablamos antes):

Esto es importante para que el entrenamiento funcione, porque necesitas que el agente tenga un sentido de si mismo, basado en su id. Entonces, el modelo que encontraras en la nube (ver referencias al final para el enlace) es el entorno de prueba, y no el entorno de entrenamiento porque queremos entrenar agentes individualmente con comportamiento egoista y no como grupo, lo que significa que para propositos de entrenamiento, el numero de agentes controlados es solo 1, pero para propositos de prueba, el numero de agentes controlados puede ser mayor.
Conclusiones
Lo que encontramos usando RL para este problema es que los negocios tienen un incentivo constante de acercarse mas y mas a los otros negocios como la mejor estrategia para conseguir mas ventas. Y la posicion en la que estos negocios se agruparan esta cerca del “centro de masa” de los clientes disponibles dentro de la ciudad, que esta cerca del centro de la ciudad si las ubicaciones de las casas y los clientes por casa estan uniformemente distribuidos.
Lo genial de este ejemplo es que hemos encontrado el equilibrio de Nash usando simulaciones y RL sin ningun incentivo mas que las ventas, lo que significa que puedes resolver otros problemas muy simples usando RL sin muchos esfuerzos de Investigacion y Desarrollo.
Tarea
No puedo terminar este articulo sin una tarea para que intentes. Imagina ahora una nueva situacion en la que los negocios se preocupan por la optimizacion social y quieren colaborar para tener ventas similares, mientras al mismo tiempo minimizan la distancia recorrida por los clientes. Como lo harias? Aun usarias Aprendizaje por Refuerzo? Preferirias usar el experimento de optimizacion o tu propio algoritmo de optimizacion? O tal vez alguna otra solucion ingeniosa? Si haces esta tarea comparte tu solucion de AnyLogic Cloud en la seccion de comentarios.
Puedes revisar y descargar este modelo directamente a traves del enlace de AnyLogic cloud:
https://cloud.anylogic.com/model/8cc811f3-b7a4-48ff-9a01-0e4f5b8e76b7?mode=SETTINGS.
Para mas detalles sobre el tema, mira el video disponible en el canal de YouTube de Noorjax Consulting: