لماذا يضع المتنافسون متاجرهم بجانب بعضهم البعض؟ - نهج التعلم المعزز العميق
هل تساءلت يومًا لماذا تضع المتاجر المادية المتنافسة نفسها بالقرب من بعضها البعض كمجموعة؟ بما أننا نعيش في عالم AnyLogic، سنستخدم المحاكاة والذكاء الاصطناعي لتحليل هذا اللغز، لكن هذا السؤال هو مسألة كلاسيكية في نظرية الألعاب، لذلك لنبدأ بمناقشة هذا من منظور نظرية الألعاب التي ستعطينا الأسس النظرية لتطوير نموذج محاكاة.
منظور نظرية الألعاب
لنتخيل متنافسَين على وشك فتح متجر جديد في مجتمع يتوزع فيه العملاء بشكل منتظم من حيث الموقع والاهتمام بالمنتج المباع. إذا تعاون المتجران مع بعضهما، يمكنهما وضع أنفسهما في مواقع تقلل متوسط المسافة التي يقطعها العميل، بينما يتقاسمان في الوقت نفسه 50% من الطلب. هذا السيناريو التعاوني هو الحل الأمثل اجتماعيًا وسيكون الجميع سعداء به.
لكن بعد أن يتصافحا ويختارا موقع متجريهما، يمكن لكل منهما بشكل فردي أن يقرر إما التعاون، أو الخيانة. يمكن تمثيل ذلك بجدول يوضح مكافآت كل صاحب متجر بناءً على القرار الذي يتخذانه، إلى جانب المكافأة للعملاء.

إذا تعاونا كلاهما، يحصل كل منهما على 50% من العملاء، ويحصل العملاء على أقصى مكافأة.
إذا خان أحدهما فقط، بالانتقال إلى وسط المدينة، يحصل على 60% من العملاء وبعض العملاء يضطرون للسفر أكثر، مما يقلل مكافأة العملاء إلى 80.
إذا خانا بعضهما البعض بالانتقال إلى وسط المدينة، يحصلان على 50% من العملاء لكن المكافأة الاجتماعية في أدنى مستوياتها لأن الناس الذين يعيشون في أطراف المدينة يضطرون الآن للسفر أكثر.
إذا فكر صاحب المتجر في مصلحته الخاصة، يُقدَّم له التفكير الاستراتيجي التالي.
-
إذا تعاون المتجر الآخر، ستُحصّل أقصى مكافأة بالخيانة.
-
إذا خان المتجر الآخر، ستُحصّل أقصى مكافأة بالخيانة.
من هذا المنظور، الخيانة هي دائمًا الاستراتيجية الأفضل، طالما لا يهتم صاحب المتجر بالسعادة الاجتماعية. خيانة كليهما لبعضهما هو توازن ناش للنظام.
هذا بالطبع نسخة مبسطة من العالم لأنه لا يأخذ في الاعتبار حقيقة أنهم قد يفقدون عملاء بسبب البعد الشديد، كما أننا لا نأخذ في الاعتبار سيكولوجية العقل البشري في هذه السيناريوهات.
نموذج المحاكاة
حسنًا، الآن بعد أن غطينا السياق، لنحاول إيجاد طريقة لتحقيق ذلك في إعداد محاكاة باستخدام AnyLogic. للقيام بذلك، نحتاج إلى عمل تجاري قادر على اتخاذ قرارات بناءً على مصالحه الأنانية؛ لكن هذا ليس بسيطًا من الناحية المفاهيمية إذا كان هناك عدة متاجر في مدينة كبيرة بالكثير من العملاء. لذلك، لتجنب الدخول في مشكلة صنع خوارزمية بأنفسنا، يمكننا استخدام التعلم المعزز (RL) مع مكافأة تساوي عدد المبيعات المُحققة. ستُنشئ هذه المكافأة شركات أنانية لا تهتم بالتحسين الاجتماعي، بل فقط بمنفعتها المالية الخاصة، وهذا جيد لأن هذا هو سلوك أصحاب المتاجر في مثال نظرية الألعاب.
المدينة مبسطة لتكون منطقة مستطيلة مع شركات ومنازل موضوعة عشوائيًا في مكان ما في تلك المنطقة. كل منزل لديه عدد عشوائي من العملاء بداخله. عندما يحتاج عميل إلى منتج (يُحدد ذلك بمعدل بسيط 1 لكل وحدة زمنية اعتباطية)، سينتقل إلى أقرب شركة وسيعود دائمًا إلى المنزل مع المنتج في يديه.
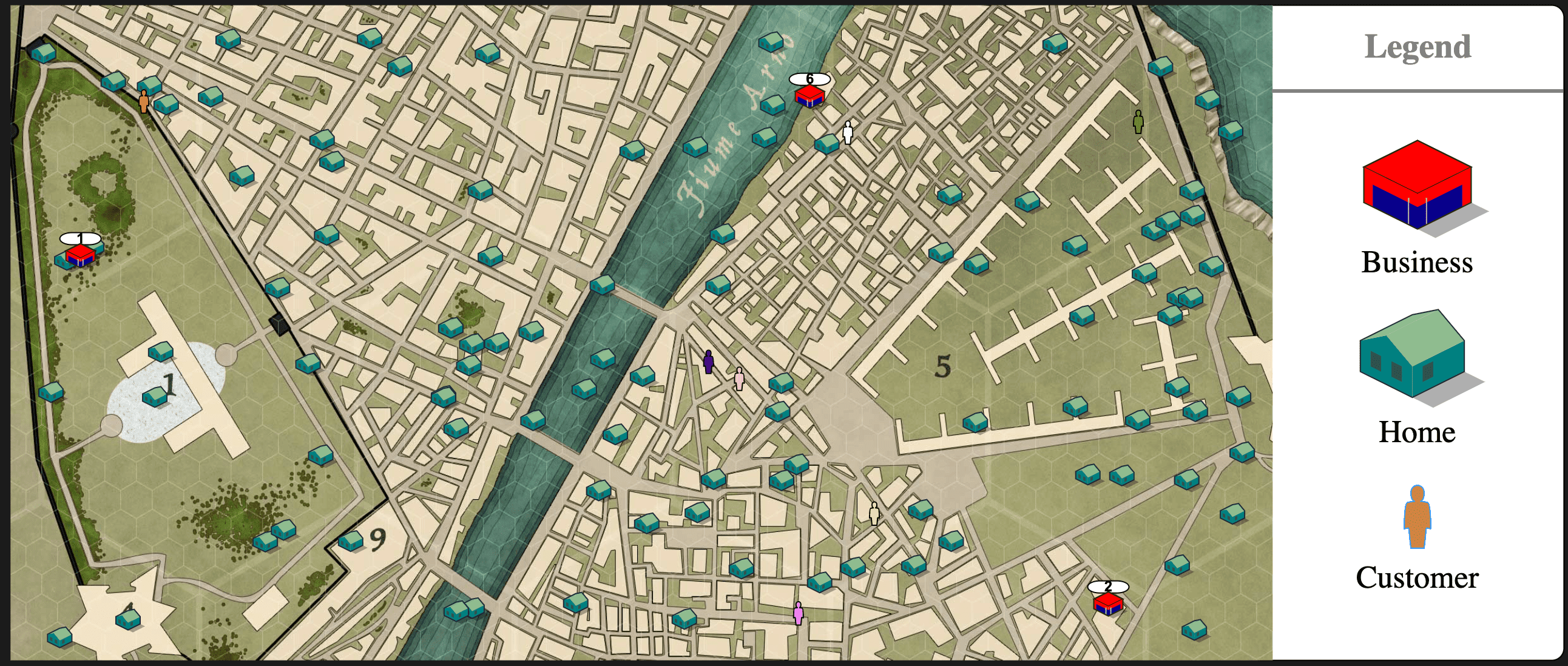
إذن، مع إنشاء النموذج العام، الآن نحتاج لجعله جاهزًا للتعلم المعزز، وإذا كنت على دراية بالتعلم المعزز، تعلم أننا نحتاج إلى إنشاء فضاء مرصود وفضاء إجراءات ومكافأة. لنرَ كلاً منها على حدة.
المرصودات
في جميع المرصودات التالية، لديك متغير يُسمى performingAgent، وهو معادل لمعرف الوكيل الذي يتخذ القرارات. هذا مهم لأن وكيلاً واحدًا فقط سيتخذ القرارات أثناء التدريب بينما يبقى الآخرون في أماكن ثابتة (سأشرح هذا لاحقًا).
إذن، هذه هي المرصودات:
-
موضع جميع المنازل في المدينة بإحداثي طبيعي يتراوح من 0 إلى 1

-
العدد الطبيعي للأشخاص في كل منزل. 0 إذا كان هناك شخص واحد فقط، و 1 إذا كان هناك

-
الإحداثيات الطبيعية للشركات الأخرى.

-
الإحداثيات الطبيعية للشركة التي تتخذ الإجراء.

المكافأة
يتم الحصول على مكافأة 1 في كل مرة تتم فيها عملية بيع.
الإجراء
تم تعريف تسعة إجراءات: أربعة منها متعلقة بالحركات الموازية لمحوري x و y، وأربعة منها للحركات القطرية والإجراء الأخير هو عدم التحرك على الإطلاق. المسافة التي يتحركها الوكيل بعد كل إجراء ثابتة ومختارة بشكل اعتباطي.
التدريب باستخدام Pathmind
حتى وقت كتابة هذا المقال، لا تمتلك Pathmind ميزة تسمح بالتدريب المستقل لعدة وكلاء يتنافسون مع بعضهم بأنظمة مكافآت مختلفة ومستقلة، لذلك ما نحتاج فعله، كما شُرح سابقًا، هو تدريب شركة فردية واحدة مع إبقاء الأخرى في موضع ثابت (أو تتحرك عشوائيًا). وإذا أردنا استخدام إعداد منافسة مع n منافسين، نحتاج إلى تدريب النموذج، مع تهيئة أولية تحدد أي شركة ستتخذ القرارات. نقوم بذلك بمتغير عشوائي كما يلي (يمثل معلمة performingAgent التي تحدثنا عنها سابقًا):

هذا مهم لكي يعمل التدريب، لأنك تحتاج أن يكون لدى الوكيل إحساس بالذات، بناءً على معرفه. لذلك، النموذج الذي ستجده على السحابة (انظر المراجع في النهاية للرابط) هو بيئة الاختبار، وليس بيئة التدريب لأننا نريد تدريب الوكلاء بشكل فردي بسلوك أناني وليس كمجموعة، مما يعني أنه لأغراض التدريب، عدد الوكلاء المُتحكَّم بهم هو 1 فقط، لكن لأغراض الاختبار، يمكن أن يكون عدد الوكلاء المُتحكَّم بهم أعلى.
الاستنتاجات
ما وجدناه باستخدام التعلم المعزز لهذه المسألة هو أن الشركات لديها حافز مستمر للتحرك أقرب وأقرب إلى الشركات الأخرى كأفضل استراتيجية لتحقيق المزيد من المبيعات. والموضع الذي ستتجمع فيه هذه الشركات قريب من “مركز الكتلة” للعملاء المتاحين داخل المدينة، وهو قريب من وسط المدينة إذا كانت مواقع المنازل والعملاء لكل منزل موزعة بشكل منتظم.
والرائع في هذا المثال أننا وجدنا توازن ناش باستخدام المحاكاة والتعلم المعزز بدون أي حافز غير المبيعات، مما يعني أنه يمكنك حل مسائل بسيطة أخرى باستخدام التعلم المعزز بدون الكثير من جهود البحث والتطوير.
واجب منزلي
لا أستطيع إنهاء هذا المقال بدون واجب منزلي لك لتجربه. تخيل الآن وضعًا جديدًا تهتم فيه الشركات بالتحسين الاجتماعي وتريد التعاون من أجل الحصول على مبيعات متشابهة، بينما في نفس الوقت تقلل المسافة التي يقطعها العملاء. كيف ستفعل هذا؟ هل ستظل تستخدم التعلم المعزز؟ هل تفضل استخدام تجربة التحسين أو خوارزمية التحسين الخاصة بك؟ أم ربما حل ذكي آخر؟ إذا قمت بهذا الواجب المنزلي شارك حل AnyLogic Cloud الخاص بك في قسم التعليقات.
يمكنك التحقق من هذا النموذج وتحميله مباشرة عبر رابط سحابة AnyLogic:
https://cloud.anylogic.com/model/8cc811f3-b7a4-48ff-9a01-0e4f5b8e76b7?mode=SETTINGS.
لمزيد من التفاصيل حول الموضوع، شاهد الفيديو المتاح في قناة YouTube الخاصة بـ Noorjax Consulting: